
たった 3 秒で、あなたの声を聞いたことがない AI があなたの声を完璧に真似ることができます。 これは、Microsoft の人工知能 (VALL-E テキスト読み上げモデル) の最新の成果であり、わずか 3 秒の発話で誰の声も意のままにコピーできます。
Microsoft VALL-E は、わずか 3 秒の発声で音声を模倣します
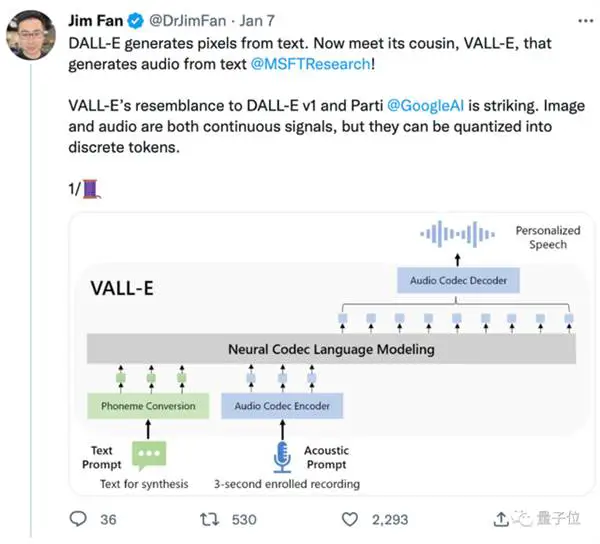
DALL E から生まれたものですが、オーディオ分野に特化しており、オンラインでリリースされた後、テキスト読み上げ効果が人気を博しました。
一部のユーザーは、VALL・EとChatGPTを組み合わせると、素晴らしい結果になると述べています. また、AI によるビデオ通話が可能になる日もそう遠くないように思われます。 AIが作家や画家を担当した後、次は声優だと冗談を言う人もいます.

しかし、VALL・Eはどのようにして「前代未聞」の音を3秒で模倣するのでしょうか?
VALL-E は、言語モデルを使用してオーディオを分析します。 AI の「聞いたことのない」音、つまりゼロサンプル学習に基づいて音声を合成します。
従来のテキスト読み上げソリューションは、基本的にプレワークアウト モードと微調整です。 サンプルがゼロのシナリオで使用すると、生成された音声の類似性と自然さが低下します。

これに基づいて、VALL-E は従来のボーカル モデルとは異なるアイデアを提案し、どこからともなく生まれました。
メルスペクトルを使用して特徴を抽出する従来のモデルと比較して、VALL-E は音声合成を言語モデルのタスクとして直接取ります。前者は連続的であり、後者は離散的です。
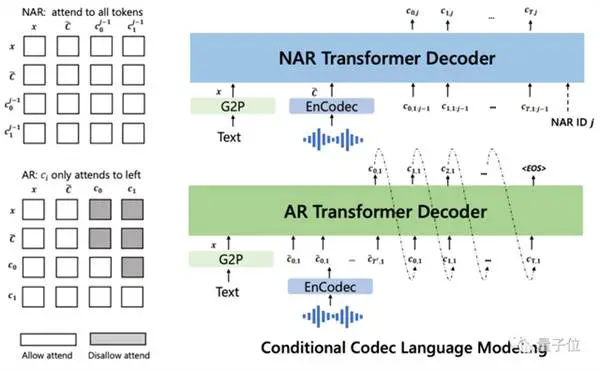
特に、従来の音声合成処理は「音素→メルスペクトログラム(mel-spectrogram)→波形」という経路であることが多い。
しかし、VALL -E はこのプロセスを「音素→離散オーディオ コーディング→波形」に変換しました。
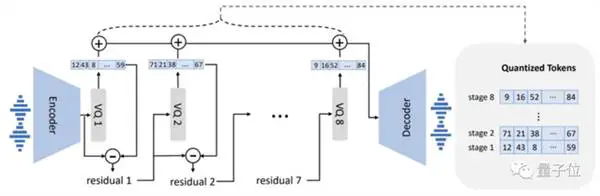
モデル設計に関しては、VALL-E も VQVAE に似ています。 オーディオを一連の個別のトークンに量子化します。 最初の量子化器は、スピーカーのオーディオ コンテンツと識別特性をキャプチャする役割を担い、XNUMX 番目の量子化器は信号の調整を担当します。 これはより自然に聞こえます:
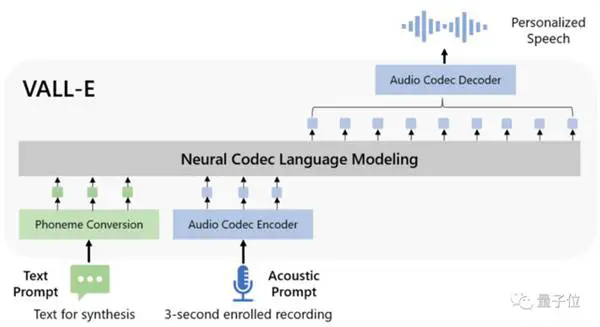
次に、テキストと 3 秒間のオーディオ プロンプトによって調整され、個別のオーディオ エンコーディングを自己回帰的に出力します。
それだけでなく、VALL-E はゼロ サンプルの音声合成に加えて、GPT-3 と組み合わせた音声編集と音声コンテンツの作成もサポートしています。
周囲の背景音も復元できます
合成されたボーカル効果から判断すると、VALL-E はスピーカーの音色以上のものを復元できます。
ピッチをその場で真似するだけでなく、さまざまな発話スピードに対応。 たとえば、これらは同じ文が XNUMX 回話されたときに VALL-E によって提供される XNUMX つの異なる発話速度ですが、トーンの類似性は依然として高いです。
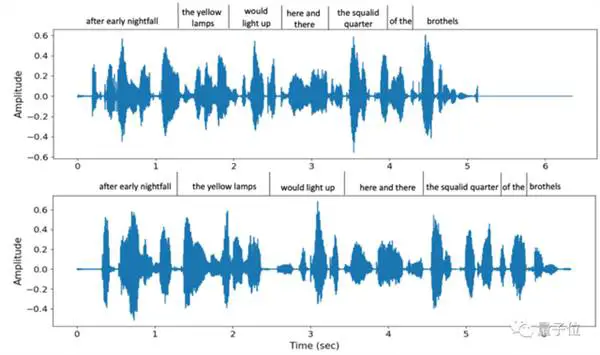
同時に、相手の背景の周囲音も正確に復元できます。
さらに、VALL-E は、怒り、眠気、中立、喜び、吐き気など、さまざまな種類の話者の感情を模倣できます。
VALL・Eトレーニングに使用されるデータセットはそれほど大きくないことに注意してください。
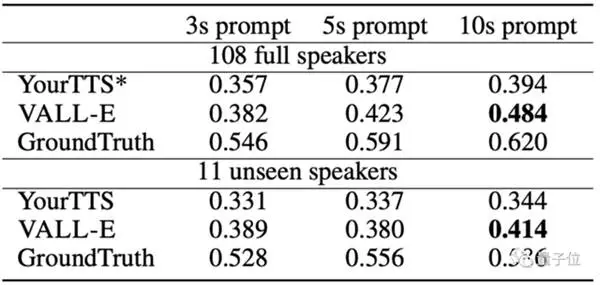
680.000 時間の音声トレーニングを必要とし、7.000 人以上のスピーカーと 60.000 時間のトレーニング時間しか使用しなかった OpenAI の Whisper と比較すると、VALL-E は、Model YourTTS テキスト読み上げとの類似性という点で、事前トレーニング済みのテキスト読み上げを上回りました。
さらに、YourTTS はトレーニング中に 97 人の話者のうち 108 人の話者の声を事前に聞いていましたが、実際のテストではまだ VALL-E に及んでいません。
適用できる分野については、次のとおりです。
障害者が他の人との会話を完了するのを助けるなど、自分の声を模倣するために使用できるだけでなく、自分が言いたくないときに自分の声を代弁するためにも使用できます。 もちろん、オーディオブックの録音にも使えます。
ただし、VALL-E はまだオープン ソースではないため、試すにはもう少し時間がかかる場合があります。







